-
파이썬을 활용한 엑셀 데이터 분석(1) - 막대그래프Develope/Python 2019. 6. 5. 16:22
import pandas as pd import xlwings as xw import matplotlib.pyplot as plt from matplotlib import font_manager, rc, style import numpy as np style.use('ggplot') def KBpriceindex_preprocessing(path, data_type): # path : KB 데이터 엑셀 파일의 디렉토리 (문자열) # data_type : '매매종합', '매매APT', '매매연립', '매매단독', '전세종합', '전세APT', '전세연립', '전세단독' 중 하나 # xlwings 모듈로 엑셀 읽기 wb = xw.Book(path) # sheet 선택 sheet = wb.sheets[data_type] # 시트 행의 개수 계산 row_num = sheet.range(1, 1).end('down').end('down').end('down').row # 읽어올 데이터 범위 설정(엑셀 열+행) data_range = 'A2:GE' + str(row_num) # options 함수로 pandas 데이터프레임에 쓰기 raw_data = sheet[data_range].options(pd.DataFrame, index=False, header=True).value big_names = '서울 대구 부산 대전 광주 인천 울산 세종 경기 강원 충북 충남 전북 전남 경북 경남 제주도 6개광역시 5개광역시 수도권 기타지방 구분 전국' bigname_list = big_names.split(' ') # 컬럼 값을 리스트로 저장 big_col = list(raw_data.columns) # 0번째 데이터를 컬럼 값으로 리스트 저장 small_col = list(raw_data.iloc[0]) # small_col 리스트의 값이 None 일 경우, big_col의 같은 열 값을 저장 for num, gu_data in enumerate(small_col): if gu_data == None: small_col[num] = big_col[num] check = num # big_col 부분 저장 알고리즘 while True: # bigname_list 를 확인 후, 해당 데이터를 기반으로 big_col을 이전의 컬럼 값으로 저장 if big_col[check] in bigname_list: big_col[num] = big_col[check] break else: check = check - 1 # 경기도 광주와 광주시의 이름이 같아서 잘못 들어간 부분 하드 코딩 big_col[129] = '경기' big_col[130] = '경기' # 원 데이터의 형식이 달라 직접 하드코딩 small_col[185] = '서귀포' # 정제한 컬럼 값들을 raw_data의 컬럼으로 직접 저장 raw_data.columns = [big_col, small_col] # drop 함수는 리스트로 지우고 싶은 행의 이름들을 넣어주면 해당 행들을 제거한 새로운 데이터프레임을 생성함 # 0,1 행을 drop 함수를 이용해 제거하고 결과를 new_col_data 변수에 저장 new_col_data = raw_data.drop([0, 1]) # 구분/구분 컬럼의 날짜 데이터를 리스트에 저장 index_list = list(new_col_data['구분']['구분']) new_index = [] # 리스트에 저장한 날짜데이터를 통일화시키기 for num, raw_index in enumerate(index_list): temp = str(raw_index).split('.') if int(temp[0]) > 12: if len(temp[0]) == 2: new_index.append('19' + temp[0] + '.' + temp[1]) else: new_index.append(temp[0] + '.' + temp[1]) else: new_index.append(new_index[num - 1].split('.')[0] + '.' + temp[0]) # set_index 함수를 이용해서 인덱스 설정 new_col_data.set_index(pd.to_datetime(new_index), inplace=True) # 필요 없어진 구분컬럼 삭제 cleaned_data = new_col_data.drop(('구분', '구분'), axis=1) return cleaned_data # 데이터 시각화 준비 font_name = font_manager.FontProperties(fname='c:/Windows/Fonts/NGULIM.TTF').get_name() rc('font', family=font_name) plt.rcParams['axes.unicode_minus'] = False # 엑셀 파일 경로 path = r'C:\Users\scent2d\Desktop\data\201904.xls' # 매매종합 시트 분석 data_type = '매매종합' new_data = KBpriceindex_preprocessing(path, data_type) # 부동산 가격지수 증감률 구하기 new_data.loc['2018-1-1'] # 데이터에 접근 시 컬럼이 아닌 인덱스를 기준으로 데이터를 가져올 때 loc를 이용 # 2016년 - 2018년 부동산 가격지수 증감률 계산 diff = (new_data.loc['2018-1-1'] - new_data.loc['2016-1-1']) / new_data.loc['2016-1-1'] * 100 # 그래프 크기 설정 fig = plt.figure(figsize=(13, 7)) # numpy 모듈을 이용해 0부터 19까지 배열을 생성 및 저장, 막대 그래프 bar의 위치로 0이 맨 밑이고 그 위로 하나씩 올라가는 형태로 인한 배열 생성 ind = np.arange(20) # subplot 설정 1행 3열의 첫 번째 sub 그래프 ax = fig.add_subplot(1, 3, 2) plt.title('2016.1 ~ 2018.1 가격 변화율 최하위 20') # barh 함수(bar 위치의 배열, 구체적인 수치의 배열, algin='center', height=0.5)를 통해 각 인덱스와 값을 입력 rects = plt.barh(ind, diff.sort_values()[:20].values, align='center', height=0.5) # yticks 함수를 통해 각 인덱스와 이름 태그를 입력 plt.yticks(ind, diff.sort_values()[:20].index) # 막대마다 수치를 달아주는 작업 for i, rect in enumerate(rects): # text 함수(값이 출력되는 X 축의 위치, 값이 출력되는 Y 축의 위치, 해당 위치에 출력할 값을 전달)를 통해 수치 매핑 ax.text(0.95 * rect.get_width(), rect.get_y() + rect.get_height() / 2.0, str(round(diff.sort_values()[:20].values[i], 2)) + '%', ha='left', va='center', bbox=dict(boxstyle="round", fc=(0.5, 0.9, 0.7), ec="0.1")) plt.show()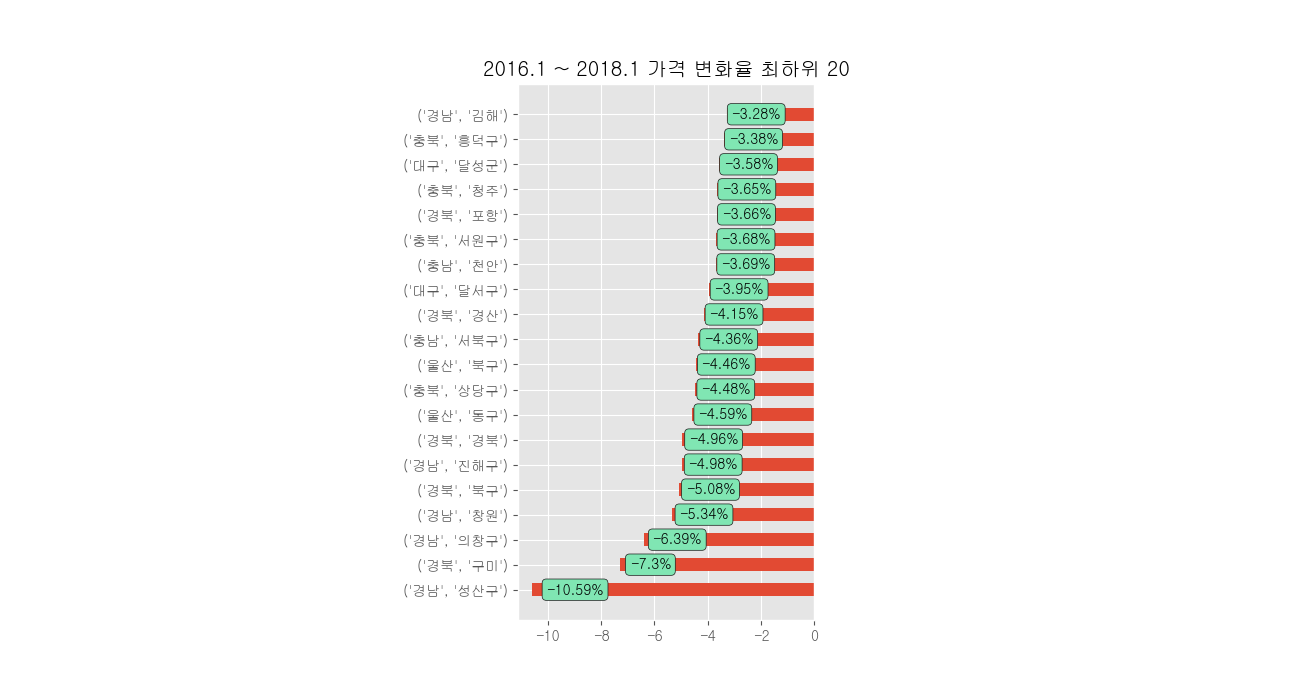
'Develope > Python' 카테고리의 다른 글
파이썬을 활용한 미니 웹 크롤러 분석(1) (0) 2019.05.28 파이썬을 활용한 엑셀 데이터 정제 - KB 가격지수 데이터 기반 (0) 2019.05.24 파이썬을 활용한 URL 인코딩/디코딩 예제 (0) 2019.04.18 댓글